| Dies sind
Unterlagen aus dem Unterricht vor 2014. 1. Bau der DNA - Zeichnung des Nukleotids mit seinen drei Bausteinen Purin - oder Pyrimidin-Base / Desoxyribose / Phosphorsäure-Verknüpfung Die Doppelhelix mit gegenläufigen 3´und 5´- Enden Buch S. 84/85 komplementäre Nukleotide: A / T (2 WBBs) und C / G (3 WBBs) . Triplettcode führt zum "Codon", den drei Nukleotiden, deren Basen jeweils eine Aminosäure codieren Gene codieren Proteine >
Ein-Gen-Ein-Enzym-Hyothese 2. Die Replikation: Verdoppelung der DNA in der Interphase. Aus den Chromatiden, die bei der Zellteilung in jedem Zellkern vom vorherigen Chromosom übrig bleiben, werden wieder Chromosomen. Dazu ist die Verdoppelung der DNA notwendig. Dies geschieht, indem der DNA-Strang reißverschlussartig geöffnet wird vom Enzym Helicase . Die Helicase trennt die Wasserstoffbrückenbindungen zwischen den einander gegenüberstehenden, also komplementären Basen in der DNA Im Plasma des Zellkerns, dem Kernplasma, schwimmen freie, also ungebundene Nukleotide herum. Diese lagern sich jeweils passend, also komplementär, an die geöffnete DNA an. Die Anlagerung und Querverknüpfung zu einem neuen DNA-Strang wird vom Enzym DNA-Polymerase durchgeführt. Das Enzym DNA-Polymerase bewegt sich durchgehend am kontinuierlichen Strang von 3´nach 5´entlang und erstellt dort einen komplementären 5´nach 3´Strang. Am diskontinuierlichen Strang stellt die DNA-Polymerase neue DNA-Bruchstücke entgegen der Laufrichtung her, in der die Helicase die DNA öffnet. Diese werden anschließend vom Enzym Ligase zum durchgehenden DNA-Strang verknüpft. Buch S. 88/89 Die Replikation verläuft semi-konservativ: beide
neu gebildeten DNA-Doppel-Stränge bestehen aus einem "alten" und
einem "neuen" DNA-Strang. Geklärt haben das Meselson & Stahl:
1958 Buch S. 87 3. die beiden Vorgänge, die von der DNA zum Protein führen: 3.1. Transkription im Zellkern: der codogene Strang der DNA (von 3´nach 5´, also entsprechend dem kontinuierlichen Strang bei der Replikation) wird mit Hilfe der RNA-Polymerase in m-RNA übersetzt. Die m-RNA wandert durch die Kernporen ins Zellplasma. RNA unterscheidet sich auf zwei Arten von DNA: a). ist der Zucker, die "Pentose" in
der Mitte ihres Nukleotids, keine Desoxy- sondern eine "normale"
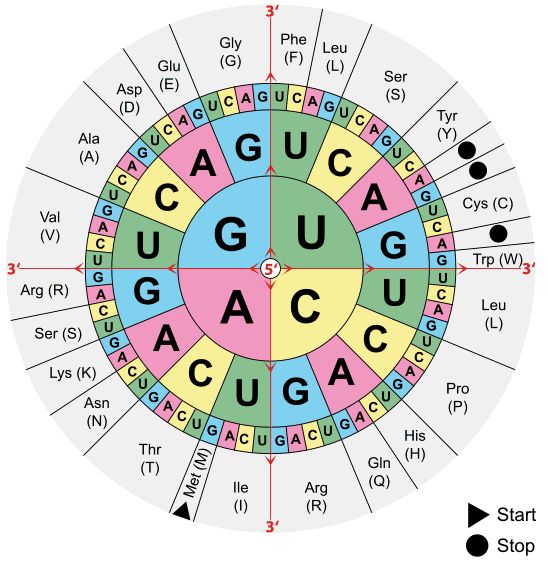
Ribonukleinsäure. Buch S. 94/95 3.2. Translation im Zellplasma, also außerhalb des Zellkerns, am Ribosom: Verknüpfen der Aminosäuren nach den Vorgaben der m-RNA aneinander zur Primärstruktur des Proteins mit Hilfe der t-RNA. (Buch S. 98) Im Zellplasma schwimmen freie, also ungebundene Aminosäuren herum. Es gibt so viele t-RNA-Sorten wie es verschiedene Aminosäure-Sorten gibt. Eine passende t-RNA bindet sich mit "ihrer" Aminosäure. Diese Kombination wird vom Ribosom erkannt und dann an eine wachsende Aminosäurekette gebunden, wenn die m-RNA mit ihrem Codon nach der betreffenden Aminosäure, die da an eine t-RNA gebunden ist, "ruft". Die Codesonne wird formuliert: http://de.wikipedia.org/wiki/Code-Sonne Nach vielen umständlichen Darstellungen der Translation hat sich ab 1972 diese runde Version schnell durchgesetzt. Die Codesonne wird von innen nach außen gelesen. Also ein Basen-Triplett in der Abfolge GGA codiert die häufig benötige Aminosäure Glycin. Innen - näher am 5´-Ende der m-RNA - beginnt mit G die Ablesung und endet außen - näher am 3´-Ende der m-RNA.
Am Buchstaben "U" erkennt man, dass hier (m-)-RNA abgelesen wird und nicht DNA. Der Triplett-Code ist "degeneriert": Es stehen 4 hoch 3 = 64 verschiedene Triplett-Codes bereit. Aber nur 20 Aminosäuren sind zu formulieren. Insbesondere die jeweils letzte Base im Triplett spielt oft keine Rolle mehr - ob A, C, A oder G: Immer wird z.B. anhand der ersten zwei Basen "GG" die Aminosäure Glycin formuliert. Der degenerierte Code hat zur Folge, dass etwa ein Zehntel aller Punktmutationen - wo also eine Base sich durch eine andere austauscht - ohne Folge bleibt. "Alle Proteine beginnen mit Methionin" könnte man meinen, da AUG das Triplett ist, bei dem die RNA-Polymerase an DNA gestartet ist (TAC liest sie dort also, das zu AUG komplementäre Triplett). Tatsächlich trifft man bei vielen, aber nicht allen Proteinen Methionin als Start der Aminosäurekette. Es gibt nämlich Enzyme, die bei Bedarf genau dieses Methionin entfernen können. Aus dem Code der m-RNA kann man einerseits auf die zukünftige Aminosäurekette schließen - nach der Translation - andererseits auch auf die Basensequenz der DNA zurückschließen. Dabei muss man aufpassen, ob vielleicht mal ein Stoppcodon vorbeihuscht - UAA, UAG oder UGA (ATT, ATC und ACT also auf der DNA). Dann bricht die Kette ab und beginnt erst wieder, wenn irgendwo in der weiteren Seqzenz AUG ´von 5´nach 3´bzw bei der DNA TAC von 3´nach 5´auftauchen: Da kann im Zellkern die Transkription eines DNA-Abschnittes beginnen. Buch S. 96, 98, 99, 100, 101 Übung: Gegeben ist ein Code. Ist es m-RNA oder DNA? Begründen Sie Ihre Antwort 5´ AAGAUGCCUUAGCUAGCUAGCCCUGA 3 Gibt es ein Startcodon? Ermitteln Sie fehlende komplementäre Sequenzen - also die zugehörige DNA- oder m-RNA-Sequenz und die Aminosäure-Sequenz. |